Private cloud integration
Private cloud integration
Before adding your cloud data to a dataset, you need to integrate your cloud storage with Encord. Please see the Data integrations section to learn how to create integrations for AWS S3 , Azure blob, GCP storage or Open Telekom Cloud.
To add your cloud data to a dataset:
- Turn on the Private cloud toggle in the 'Create dataset' part of the data creation flow when creating a new dataset.
- Select the relevant integration using the Select integration drop down.
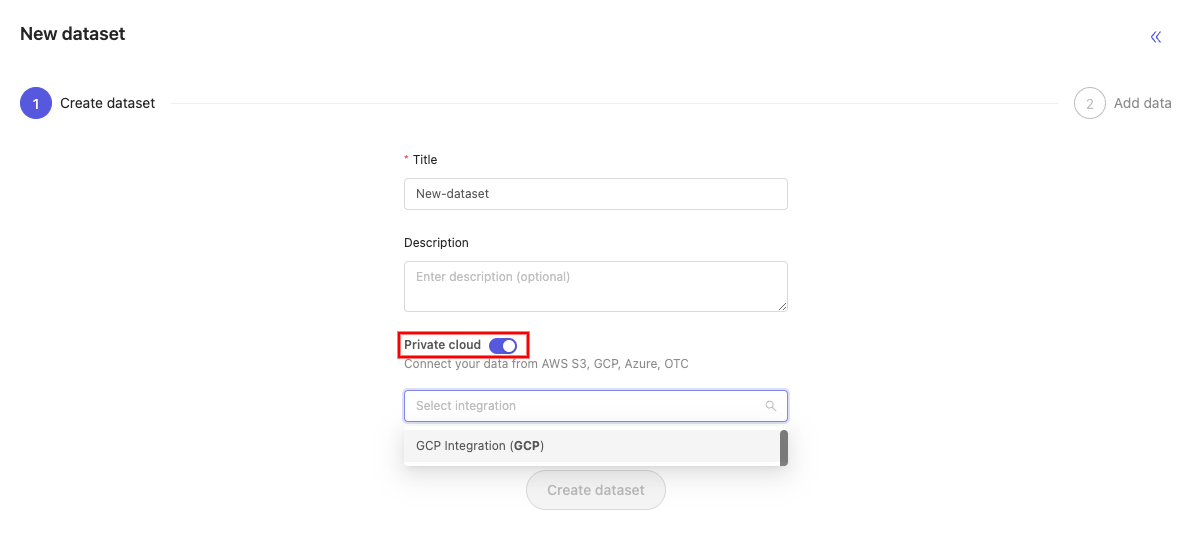
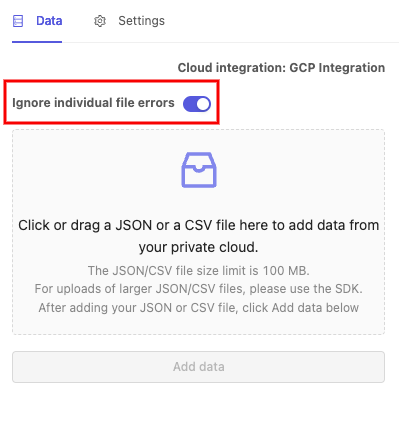
- Upload an appropriately formatted JSON or CSV file specifying the data you would like to add to the dataset.
- Click the upload area, or drag-and-drop your files from your storage container. Your stored objects may contain files which are not supported by Encord and which may produce errors on upload - toggle the Ignore individual file errors toggle to ignore these. Click Add data when you're ready.
The data will now be fetched from your cloud storage and processed asynchronously. This processing involves fetching appropriate metadata and other file information to help us render the files appropriately and to check for any framerate inconsistencies. We do not store your files in any way.
Checking upload status
You can check the progress of the processing job by clicking ![]() in the top right.
A spinning progress indicator will indicate the processing job is still in progress.
in the top right.
A spinning progress indicator will indicate the processing job is still in progress.
- If successful, the processing will complete with a
 icon.
icon. - If unsuccessful, there will be a
 icon, as seen below.
icon, as seen below.
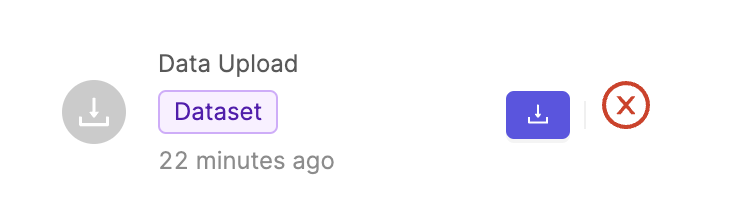
If this is the case, please check that your provider permissions have been set correctly, that the object data format is supported, and that the JSON or CSV file is correctly formatted.
Check which files failed to upload by clicking the ![]() icon to download a CSV log file. Every row in the CSV will correspond to a file which failed to be uploaded.
icon to download a CSV log file. Every row in the CSV will correspond to a file which failed to be uploaded.
You will only see failed uploads if the Ignore individual file errors toggle wasn't enabled when uploading your data.
JSON format
The JSON file format is a JSON object with top-level keys specifying the type of data and object URLs of the content
you wish to add to the dataset. Object URLs must not contain any whitespace. You can add one data type at a time, or
combine multiple data types in one JSON file according to your preferences or development flows. The supported top-level keys are: videos, image_groups, image_sequences, images, and dicom_series. The details for each data format are given in the sections below.
Videos
Videos
Each object in the videos array is a JSON object with the key objectUrl specifying the full URL of where to find the video resource. The title field is optional. If not specified, the video's file name will be used.
Video metadata (separate from client metadata) may be specified for videos. Click here to read more.
If
skip_duplicate_urlsis set totrue, image groups where all object URLs exactly match an existing image group in the dataset will be skipped.
| Key or Flag | Required? | Default value |
|---|---|---|
| "objectUrl" | Yes | |
| "title" | No | <file title> |
| "clientMetadata" | No | |
| "skip_duplicate_urls" | No | false |
| "createVideo" | No | false |
See the sample below.
{
"videos": [
{
"objectUrl": "<object url_1>"
},
{
"objectUrl": "<object url_2>",
"title": "my-custom-video-title.mp4",
"clientMetadata": {"optional": "metadata"}
}
],
"skip_duplicate_urls": true
}
Single images
Single Images
The JSON structure for single images parallels that of videos.
- The
titlefield is optional. - If not specified, the file name of the image will be used.
- If
skip_duplicate_urlsis set totrue, images that have been previously uploaded to the dataset with the same object URL will be skipped.
| Key or Flag | Required? | Default value |
|---|---|---|
| "objectUrl" | Yes | |
| "title" | No | <file title> |
| "clientMetadata" | No | |
| "skip_duplicate_urls" | No | false |
| "createVideo" | No | false |
See the sample below.
{
"images": [
{
"objectUrl": "<object url>"
},
{
"objectUrl": "<object url>",
"title": "my-custom-image-title.jpeg",
"clientMetadata": {"optional": "metadata"}
}
]
}
Image groups
Image groups
- Image groups are collections of images that are processed as one annotation task.
- Images within image groups remain unaltered, meaning that images of different sizes and resolutions can form an image group without the loss of data.
- Image groups do not require 'write' permissions to your cloud storage.
- Custom client metadata is defined per image group, not per image.
- If
skip_duplicate_urlsis set totrue, image groups where all object URLs exactly match an existing image group in the dataset will be skipped.
| Key or Flag | Required? | Default value |
|---|---|---|
| "objectUrl" | Yes | |
| "title" | Yes | <file title> |
| "clientMetadata" | No | |
| "skip_duplicate_urls" | No | false |
| "createVideo" | No | false |
The position of each image within the sequence needs to be specified in the key - e.g. objectUrl_{position_number} as seen in the example below. Images will be stored in reverse order to the position numbers they are assigned.
{
"image_groups": [
{
"title": "<title 1>",
"createVideo": false,
"objectUrl_0": "<object url>"
},
{
"title": "<title 2>",
"createVideo": false,
"objectUrl_0": "<object url>",
"objectUrl_1": "<object url>",
"objectUrl_2": "<object url>",
"clientMetadata": {"optional": "metadata"}
}
]
}
Image sequences
Image sequences
Image sequences are collections of images that are processed as one annotation task and represented as a video.
Images within image sequences may be altered as images of varying sizes are resolutions are made to match that of the first image in the sequence.
Creating Image sequences from cloud storage requires 'write' permissions, as new files have to be created in order to be read as a video.
Each object in the
image_sequencesarray represents a single image sequence.Custom client metadata is defined per image sequence, not per image.
If
skip_duplicate_urlsis set totrue, image groups where all object URLs exactly match an existing image group in the dataset will be skipped.Key or Flag Required? Default value "objectUrl" Yes "title" Yes < file title>"clientMetadata" No "skip_duplicate_urls" No false "createVideo" Yes false
The position of each image within the sequence needs to be specified in the key - e.g objectUrl_{position_number}. See the example below.
{
"image_sequences": [
{
"title": "<title 1>",
"createVideo": true,
"objectUrl_0": "<object url>"
},
{
"title": "<title 2>",
"createVideo": true,
"objectUrl_0": "<object url>",
"objectUrl_1": "<object url>",
"objectUrl_2": "<object url>",
"clientMetadata": {"optional": "metadata"}
}
]
}
DICOM
DICOM
Like
image_groupsandimage_sequences, thedicom_serieselements require a title and a sequenced object URL. See the sample below.Custom client metadata is defined per DICOM series
If
skip_duplicate_urlsis set totrue, image groups where all object URLs exactly match an existing image group in the dataset will be skipped.Key or Flag Required? Default value "objectUrl" Yes "title" Yes < file title>"clientMetadata" No "skip_duplicate_urls" No false "createVideo" Yes false
{
"dicom_series": [
{
"title": "<title 1>",
"objectUrl_0": "<object url>"
},
{
"title": "<title 2>",
"objectUrl_0": "<object url>",
"objectUrl_1": "<object url>",
"objectUrl_2": "<object url>",
"clientMetadata": {"optional": "metadata"}
}
]
}
Multiple file types
You can upload multiple file types using a single JSON file. The example below shows 1 image, 2 videos, 2 image sequences, and 1 image group.
{
"images": [
{
"objectUrl": "https://cord-dev.s3.eu-west-2.amazonaws.com/Image1.png"
}
],
"videos": [
{
"objectUrl": "https://cord-dev.s3.eu-west-2.amazonaws.com/Cooking.mp4"
},
{
"objectUrl": "https://cord-dev.s3.eu-west-2.amazonaws.com/Oranges.mp4"
}
],
"image_sequences": [
{
"title": "apple-samsung-light",
"createVideo": true,
"objectUrl_0": "https://cord-dev.s3.eu-west-2.amazonaws.com/food-dataset/Apple/1-Samsung-S4-Light+Environment/1+(32).jpg",
"objectUrl_1": "https://cord-dev.s3.eu-west-2.amazonaws.com/food-dataset/Apple/1-Samsung-S4-Light+Environment/1+(33).jpg",
"objectUrl_2": "https://cord-dev.s3.eu-west-2.amazonaws.com/food-dataset/Apple/1-Samsung-S4-Light+Environment/1+(34).jpg",
"objectUrl_3": "https://cord-dev.s3.eu-west-2.amazonaws.com/food-dataset/Apple/1-Samsung-S4-Light+Environment/1+(35).jpg"
},
{
"title": "apple-samsung-dark",
"createVideo": true,
"objectUrl_0": "https://cord-dev.s3.eu-west-2.amazonaws.com/food-dataset/Apple/2-samsung-S4-Dark+Environment/2+(32).jpg",
"objectUrl_1": "https://cord-dev.s3.eu-west-2.amazonaws.com/food-dataset/Apple/2-samsung-S4-Dark+Environment/2+(33).jpg",
"objectUrl_2": "https://cord-dev.s3.eu-west-2.amazonaws.com/food-dataset/Apple/2-samsung-S4-Dark+Environment/2+(34).jpg",
"objectUrl_3": "https://cord-dev.s3.eu-west-2.amazonaws.com/food-dataset/Apple/2-samsung-S4-Dark+Environment/2+(35).jpg"
}
],
"image_groups": [
{
"title": "apple-ios-light",
"createVideo": false,
"objectUrl_0": "https://cord-dev.s3.eu-west-2.amazonaws.com/food-dataset/Apple/3-IOS-4-Light+Environment/3+(32).jpg",
"objectUrl_1": "https://cord-dev.s3.eu-west-2.amazonaws.com/food-dataset/Apple/3-IOS-4-Light+Environment/3+(33).jpg"
}
]
}
Specifying video metadata
The JSON format allows you to specify metadata for video files. Metadata is essential information used by the label editor and crucial for aligning annotations to the correct frame.
Example JSON including video metadata
{
"videos": [
{
"objectUrl": "video_file.mp4",
"videoMetadata": {
"fps": 23.98,
"duration": 29.09,
"width": 1280,
"height": 720,
"file_size": 5468354,
"mime_type": "video/mp4"
}
}
]
}
- fps: Frames per second.
- duration: Duration of the video (in seconds).
- width / height: Dimensions of the video (in pixels).
- file_size: The size of the file (in bytes).
- mime_type: Specifies the file type extension according to the MIME standard.
When videos are supplied with video metadata, Encord assumes the metadata to be correct and our servers will neither download nor pre-process your data. This may be a particularly useful feature for customers with strict data compliance concerns.
One way to find the necessary metadata is shown below. Run the following commands in your terminal.
ffmpeg -i 'video_title.mp4'to retrieve fps, duration, width, and height - as highlighted below.
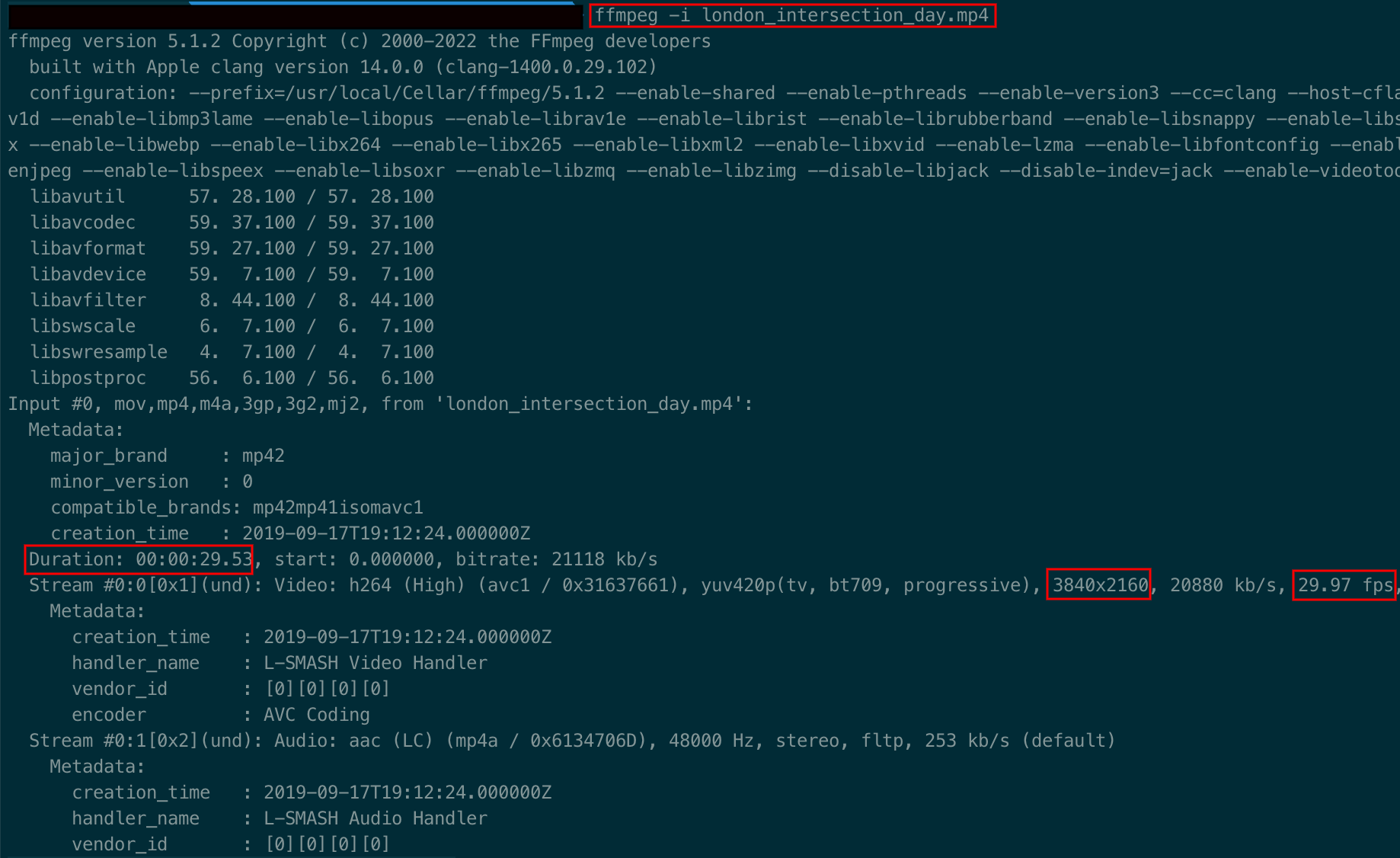
ls -l 'video_title.mp4'to retrieve the file size - as highlighted below.

You can optionally add some custom client metadata per data item in the clientMetadata field.
See examples below on how to add this. Note that client metadata is separate from video metadata above,
and is intended as an arbitrary store of data you would like to associate with any particular file.
It is important to know that we enforce a 10MB limit on the client metadata per data item.
Also, this metadata is being stored as a PostgreSQL jsonb type internally.
Please read the relevant PostgreSQL docs about the jsonb type and its behaviours.
For example, jsonb type will not preserve key order or duplicate keys.
Add the "skip_duplicate_urls": true flag at the top level to make the uploads idempotent.
Skipping URLs already in the dataset can help complete large upload operations, which may have been interrupted due to unstable network, etc. Since previously processed assets don't have to be uploaded again, you can simply retry the failed operation without editing the upload specification file. The default of this flag is set to false. The default of this flag is set to false.
This feature is currently only supported for the JSON uploads.
When using a Multi-Region Access Point
When using a Multi-Region Access Point for your AWS S3 buckets the JSON file will have to be slightly different than the examples provided. Instead of an object's URL, objects are specified using the ARN of the Multi-Region Access Point followed by the object name. The example below shows how video files from a Multi-Region Access Point would be specified.
{
"videos": [
{
"objectUrl": "Multi-Region-Access-Point-ARN + <object name_1>"
},
{
"objectUrl": "Multi-Region-Access-Point-ARN + <object name_2>",
"title": "my-custom-video-title.mp4",
"clientMetadata": {"optional": "metadata"}
}
],
"skip_duplicate_urls": true
}
CSV format
The CSV file format is a CSV file where the columns specify the type of data and object URLs of the content you wish to add to the dataset. Object URLs must not contain any whitespace. You can add one data type at a time, or combine multiple data types in one CSV file according to your preferences or development flows.
The details for each data format are given in the sections below.
We do not currently support DICOM, or single image files in the CSV format.
Videos
Videos
A CSV file containing image groups should be structured with three columns with the following headings: 'ObjectURL', 'Title', and 'Create video'.
The 'ObjectURL' column containing the
objectUrl. It specifies the full URL of where to find the video resource.The Title column containing the
video_title. Entering avideo_titleis optional, and if left blank will default to the video's title.The 'Create video' column containing the value
false. If left blank it will default tofalse.
| ObjectUrl | Title | Create video |
|---|---|---|
<object url> | <video_title> | false |
Image groups
Image groups
A CSV file containing image groups should be structured with three columns with the following headings: 'ObjectURL', 'Title', and 'Create video'.
The 'ObjectURL' column containing the
objectUrl. It specifies the full URL of where to find the image resource.Entering an
Image group titleis mandatory, as it will signify the name of the image group and image should be assigned to.The 'Create video' column containing the value
false. If left blank it will default tofalse.
| ObjectUrl | Image group title | Create video |
|---|---|---|
<object url> | <image_group_title> | false |
Image groups do not require 'write' permissions.
Image sequences
Image sequences
A CSV file containing image sequences should be structured with three columns with the following headings: 'ObjectURL', 'Title', and 'Create video'.
The 'ObjectURL' column containing the
objectUrl. It specifies the full URL of where to find the image resource.Entering an
Image sequence titleis mandatory, as it will signify the name of the image group and image should be assigned to.The 'Create video' column containing the value
true. This is the only file type where for which you can't leave this column blank.
| ObjectUrl | Image sequence title | Create video |
|---|---|---|
<object url> | <image_sequence_title> | true |
Image sequences require 'write' permissions against your storage bucket to save the compressed video.
Multiple file types
Multiple file types
You can upload multiple file types with a single CSV file. The example below shows 2 videos, 1 single image, 2 image sequences, and an image group.
| ObjectUrl | Title | Create video |
|---|---|---|
<object url> | <video_title 1> | |
<object url> | <video_title 2> | |
<object url> | <image_title 1> | |
<object url> | <image_sequence_title 1> | true |
<object url> | <image_sequence_title 2> | true |
<object url> | <image_group_title 1> | false |
Helpful Scripts and Examples
Use the following examples and helpful scripts to quickly learn how to create JSON and CSV files formatted for the dataset creation process, by constructing the URLs from the specified path in your private storage.
AWS S3
AWS S3 object URLs can follow a few set patterns:
- Virtual-hosted style:
https://<bucket-name>.s3.<region>.amazonaws.com/<key-name> - Path-style:
https://s3.<region>.amazonaws.com/<bucket-name>/<key-name> - S3 protocol:
S3://<bucket-name>/<key-name> - Legacy: those without regions or those with
S3-<region>in the URL
AWS best practice is to use Virtual-hosted style. Path-style is planned to be deprecated and the legacy URLs are already deprecated.
We support Virtual-hosted style, Path-style and S3 protocol object URLs. We recommend you use Virtual-hosted style object URLs wherever possible.
Object URLs can be found in the Properties tab of the object in question. Navigate to AWS S3 > bucket > object > Properties to find the Object URL.
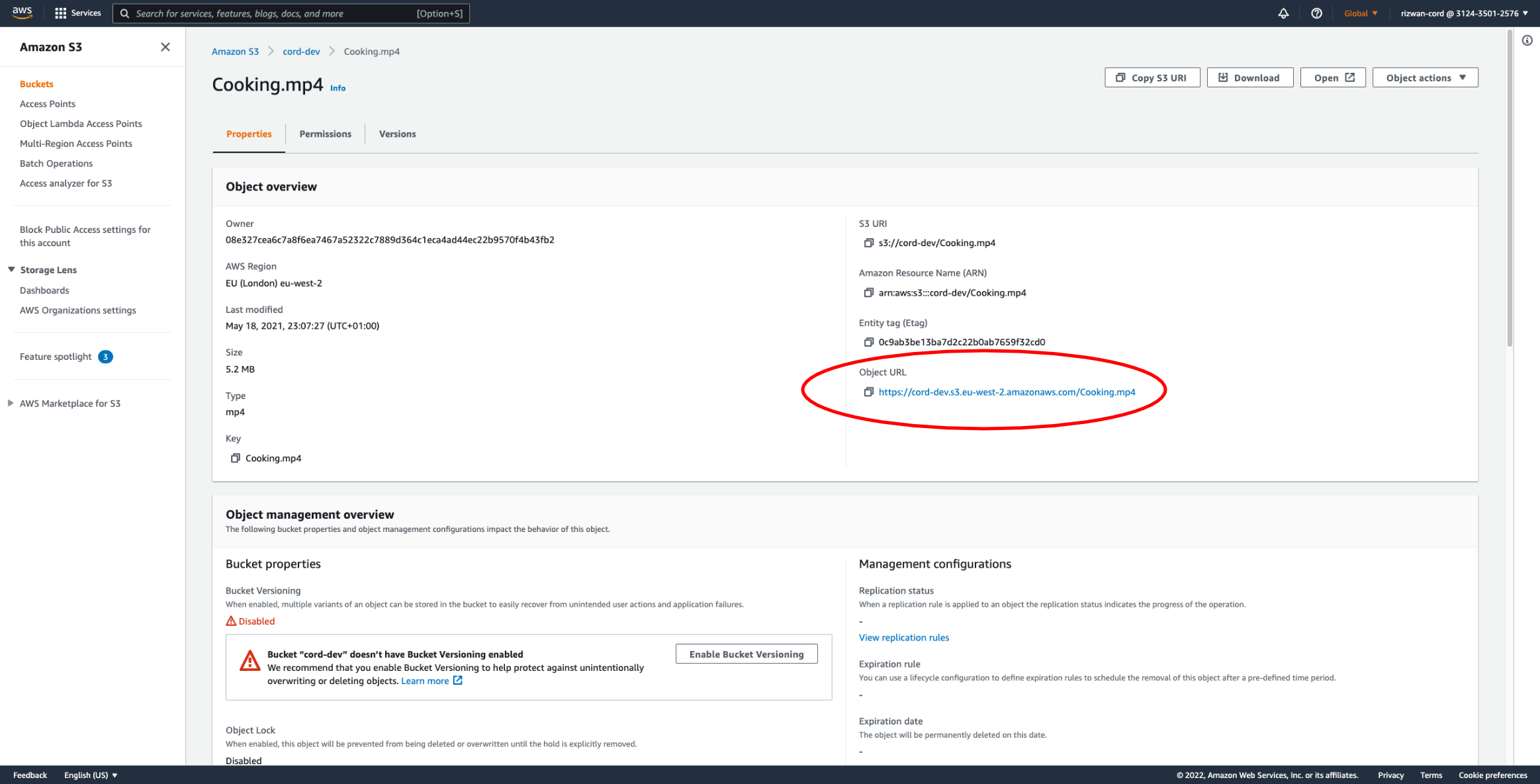
Here's a python script which creates a JSON file for single images by constructing the URLs from the specified path in a given S3 bucket. You'll need to configure the following variables to match your setup.
- region: needs to be the AWS resource region you intend to use. For S3, it's the region where your bucket is.
- aws_profile: is the name of the profile in the AWS ~/.aws/credentials file. See AWS Credentials Documentation to set up the credentials file properly.
- bucket_name: the name of your S3 bucket you want to pull files from.
- s3_directory: the path to the directory where your files are stored inside the S3 bucket. Include all slashes but final slash. For example:
# my file is at my-bucket/some_top_level_dir/video_files/my_video.mp4
# then set s3 directory as follows
s3_directory = 'some_top_level_dir/video_files'
And the script itself:
import boto3
import logging
import sys
import json
from botocore.config import Config
region = 'FILL_ME_IN'
aws_profile = 'FILL_ME_IN'
bucket_name = 'FILL_ME_IN'
s3_directory = 'FILL_ME_IN'
domain = f's3.{region}.amazonaws.com'
root_url = f'https://{domain}/{bucket_name}'
session = boto3.Session(profile_name=aws_profile)
sandbox_s3_client = session.client('s3')
s3 = boto3.resource('s3')
bucket = s3.Bucket(bucket_name)
images = []
for object_summary in bucket.objects.all():
split_key = object_summary.key.split('/')
if len(split_key) >= 2 and '/'.join(split_key[0:-1]) == s3_directory:
object_url = f'{root_url}/{object_summary.key}'
images.append({'objectUrl': object_url})
outer_json_dict = {
"images": images
}
output_file = open(f'upload_images_{s3_directory}.json', 'w')
json.dump(outer_json_dict, output_file, indent=4)
output_file.close()
Azure blob
{
"videos": [
{
"objectUrl": "https://myaccount.blob.core.windows.net/myblob"
},
{
"objectUrl": "https://myaccount.blob.core.windows.net/mycontainer/myblob.jpg"
},
{
"objectUrl": "https://myaccount.blob.core.windows.net/mycontainer/myblobs/myblob.jpg"
}
],
"image_groups": [
{
"title": "image_group_1",
"objectUrl_0": "https://myaccount.blob.core.windows.net/mycontainer/myblob1.jpg",
"objectUrl_1": "https://myaccount.blob.core.windows.net/mycontainer/myblob2.jpg"
},
{
"title": "image_group2",
"objectUrl_0": "https://myaccount.blob.core.windows.net/mycontainer/myblob3.jpg",
"objectUrl_1": "https://myaccount.blob.core.windows.net/mycontainer/myblob4.jpg"
}
]
}
GCP storage
{
"videos": [
{
"objectUrl": "gs://example-url/object.mp4"
}
],
"image_groups": [
{
"title": "image_group_1",
"objectUrl_0": "https://storage.cloud.google.com/example-image-bucket/object_1.jpg",
"objectUrl_1": "https://storage.cloud.google.com/example-image-bucket/object_2.jpg"
},
{
"title": "image_group_2",
"objectUrl_0": "https://storage.cloud.google.com/example-image-bucket/object_3.jpg",
"objectUrl_1": "https://storage.cloud.google.com/example-image-bucket/object_4.jpg"
}
]
}
Open Telekom Cloud OSS
{
"dicom_series": [
{
"title": "OPEN_TELEKOM_DICOM_SERIES",
"objectUrl_0": "https://bucket-name.obs.eu-de.otc.t-systems.com/dicom-file-0",
"objectUrl_1": "https://bucket-name.obs.eu-de.otc.t-systems.com/dicom-file-1",
"objectUrl_2": "https://bucket-name.obs.eu-de.otc.t-systems.com/dicom-file-2",
"objectUrl_3": "https://bucket-name.obs.eu-de.otc.t-systems.com/dicom-file-3"
}
]
}