Creating training projects
Training projects are the perfect tool for quickly bringing new annotators up to speed on understanding new data types or modalities, or learning a new ontology for data they may already be familiar with. Additionally, training projects are an excellent way to train team members new to the Encord annotation platform, even if they're already familiar with certain types of data.
The essential premise of the training projects is that annotators or experts you trust to label the data provide a standard to match -- the ground-truth labels -- then, we leverage our powerful automatic quality assurance functionality to automatically benchmark trainees against the ground-truth.
This means that after creating a training project, you can easily scale your training operations to tens, hundreds, or even more team members and the evaluations will all be done automatically. Trainee supervisors and administrators need only check the performance dashboard to quickly understand annotator performance against the ground-truth as a whole, or find troublesome or difficult annotations that many members seem to mistake.
Follow the steps below to create a training project, or head over to working with training projects if you want to learn how to manage an existing training project.
1. Create the source project(s)
In Encord, labels are stored at the project level. Recall that projects represent the union of an ontology, dataset(s), and team member(s) that come together to produce a set of labels. In this case, we're interested in first creating our ground-truth labels. Since the ground-truth labels may also be known as the source of truth and are stored in a project, we call the project storing ground-truth labels, the ground-truth source project or simply source project for short.
Training source projects are currently stored as production labeling projects in Encord. Follow the Project creation flow to create your eventual source project. Pay special attention to the ontology you select, as you will need to select the exact same ontology when creating the training project.
2. Create the ground-truth labels
After you've created the source project, you need to add the ground-truth labels. You can add ground-truth labels by annotating data inside our label editor, or upload labels using the SDK.
The Encord system must know that a labeling task has been annotated before it can be used as a ground-truth source. In order to be used as a ground-truth task, the task's status must be either 'In review' or 'Completed'. A good rule to follow is that the task should appear in the source project's Labels Activity tab with a status of 'In review' or 'Completed'.
If you're using the SDK, you can use the method submit_label_row_for_review to programmatically put labels into the ground-truth label set.
If you don't need to manually review ground-truth labels, for example, when importing them from known sources of truth, you can set a Manual QA Project's "sampling rate" to 0 -- which will send all labeling tasks straight to 'Completed' without entering the review phase.
Now that you've created the source project(s) and prepared the ground-truth labels, you're ready to create the training project itself.
3. Create the training project
We'll walk through assuming just one source project, but the process is extensible for as many source projects as you may need.
Name the training project
This step is analogous to naming an annotation project. Choose an easy to recognize name, and set an optional description if you wish.
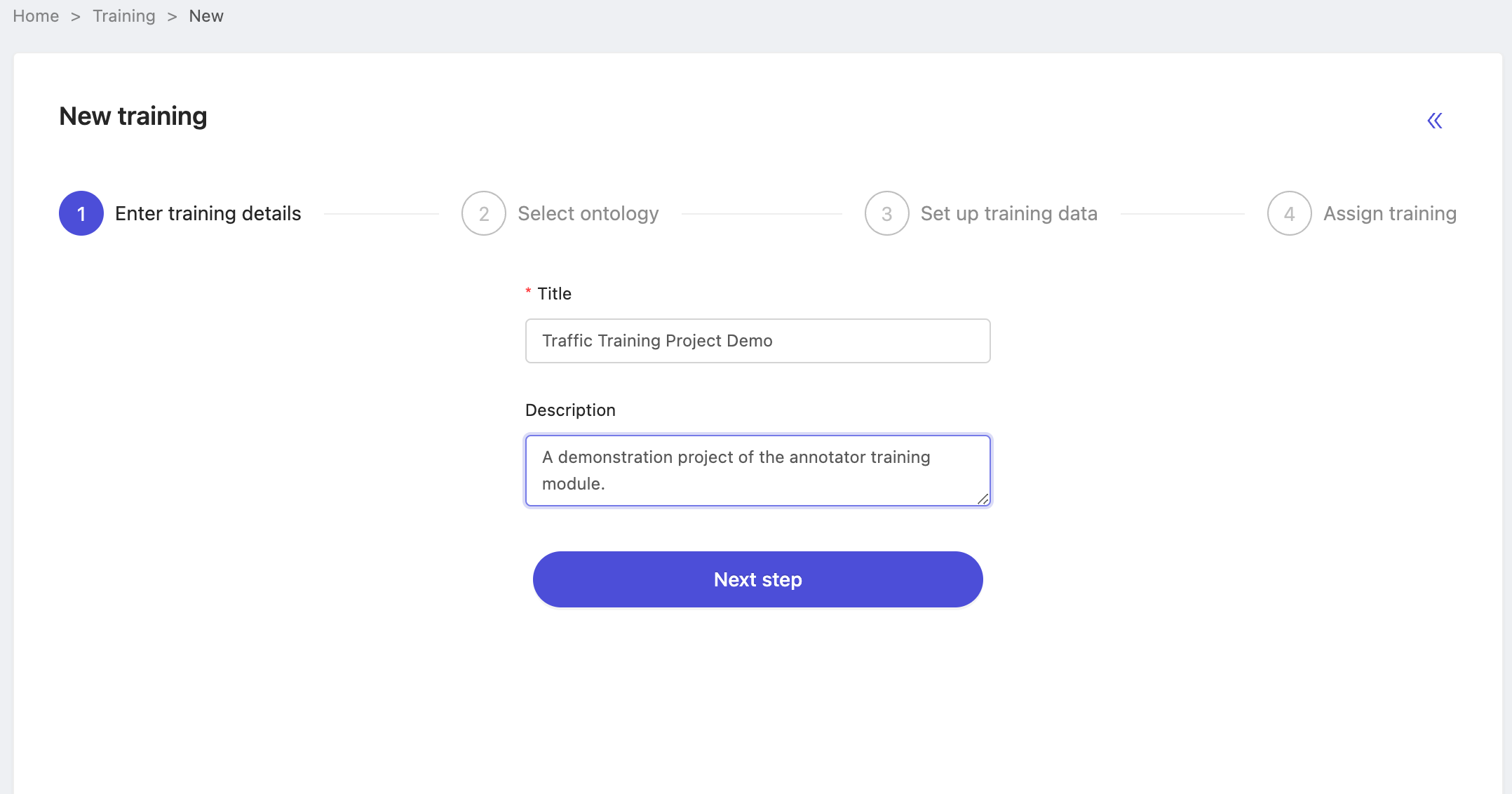
Select the ontology
The most important point to keep in mind when choosing an ontology for the annotator training project is that you must choose the same ontology as is used by your intended ground-truth source projects. The annotator training evaluation function works by comparing labels in benchmark tasks vs those in the ground-truth project. Even if the underlying dataset is the same, we are unable to match labels unless they originate from the same ontology, so this is an important step!
Other than the need to match ontology to your source projects however, choosing an ontology is analogous to that of choosing for an annotation project. Click 'Next' after you've confirmed your selection. You can return to this step if you need to choose a different ontology in order to match your desired ground-truth source project(s).
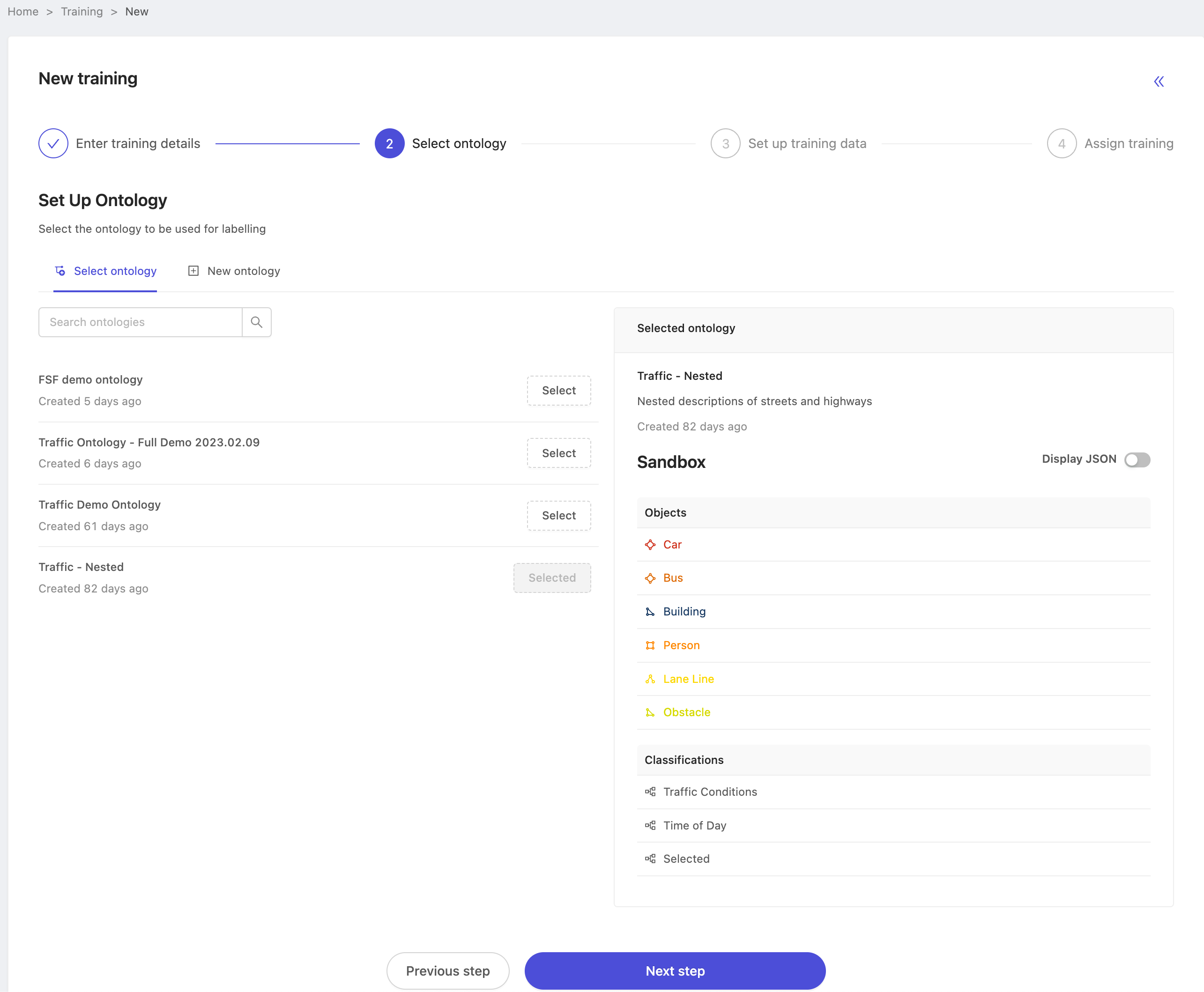
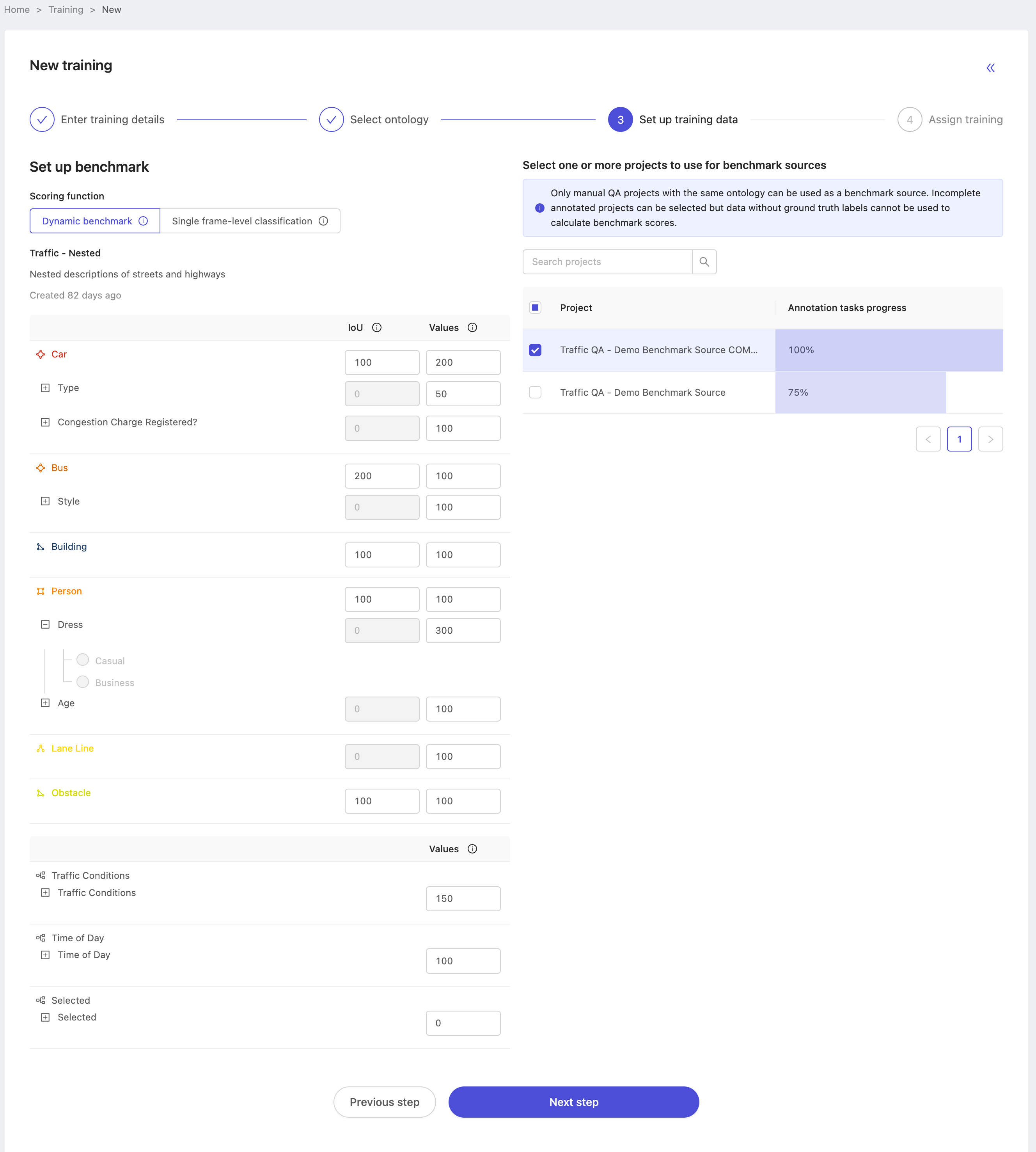
Setup training data
The training data step is where you configure two important settings for a training project.
- Choose the project(s) which contain the desired ground-truth labels. When getting started, we recommend choosing source project(s) with 100% annotation task progress. We can only use annotated tasks as benchmark evaluation tasks, so using a project with 100% annotation task progress ensures there are no surprises in relation to which tasks appear in the evaluation task set.
- Set up the initial configuration of the benchmark function. We refer to it as a benchmark evaluation function because
trainees are benchmarked against the ground-truth, and their performance is calculated according to weights you define
over the different label categories and nested attributes. By default, each category and nested attribute carry equal
weight -- the default is represented as
100.
Here, we've selected a single source project with 100% annotation progress, and customized the benchmark function for several ontology classes, reflecting which classes and attributes have greater or lesser importance when evaluating annotator performance. Once you're satisfied with your configuration press 'Next' to continue.
Selection of the source project(s) is final after training project creation, but you can always adjust the benchmark function later, even after project creation. Do not spend too long optimizing your scoring function at this stage. It's best to make an initial guess at your desired configuration, then edit and re-calculate after observing trainee performance.
Some teams may need further insight into the details of the benchmark function in order to devise an accurate system. However, detailed knowledge of the benchmark function may unduly influence trainees behavior. Please contact Encord directly at support@encord.com and we'll be more than happy to provide further material on the benchmark process to your administration team. This allows us to empower our customers while protecting the integrity of the benchmarking process.
Assign trainees and create the project
The final step is to add the initial set of annotator trainees to the project. Use this opportunity to add training project participants, either from a group, or as individuals. Note also this does not have to be the final set of project participants. If you're unsure, you can always add annotators later.
Press 'Create training program' to create the training project, which will return you to the projects list with your newly created training project. Proceed to working with training projects to learn how to work with your newly created training project!